Trends Edge Technologies
Delivering Solutions with Technology Edge
Delivering Solutions with Technology Edge

Gartner inquiries about “big data,” as much as I have always hated the term, continue to be frequent but Hadoop ones are not. In the past 24 months, our data management analysts have advised clients with 750 “big data” inquiries – 31 or so a month, still a substantial volume. For perspective, in the same period, there were 1750 about data lakes. (There is some overlap, and I have not attempted to tease them apart.) If you’re wondering about “lakehouse,” it’s less than a tenth of that, and mostly in the past few months, but it’s rising rapidly.
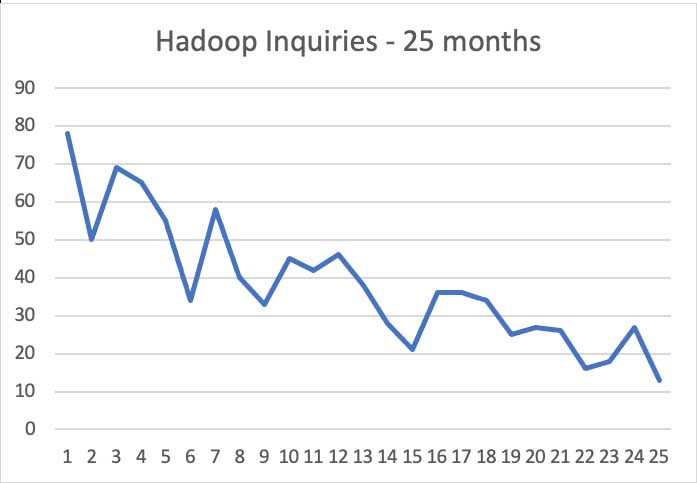
Tracking these things is a good way for Gartner to hear what the market is saying – it informs our coverage, directs our research, and focuses our attention. The “Hadoop” story is instructive. It has come up only 366 times over the same period, and the trend is very clear, as the figure below shows.
This should not surprise anyone. After all, Cloudera announced its Enterprise Data Hub 8 years ago in 2014. Its messaging rapidly moved away from marketing based on “Hadoop” and embraced Spark, Kafka, Flink, NiFi and other key open source developments over the next few years, and its competitors did the same. In fact, Cloudera, Databricks, Dremio, Ververica and other software vendors continue to watch developing open source components and use them to enhance their commercial offerings – and return the favor by contributing code to those projects.
The statistics don’t tell you what the “Hadoop” inquiries are about, but that has undergone a change as well. Two years ago, in the Hype Cycle for Data Management, 2020, Gartner discussed the emerging interest in SQL Access to Hadoop and SQL Access to Object Stores – based in large part on inquiries we were receiving. That trend was so pronounced we began covering a new category called Analytics Query Accelerators, products promising to improve performance against unoptimized data lake data, with acceleration technology often built on open source offerings. Many of the data teams’ “Hadoop” inquiries have moved over there. I posted my last Project Tracker updating which open source project versions were in commercial Hadoop offerings a few months later. The continuing inquiry traffic is increasingly about where to put the data first assembled for use with the original Hadoop toolset, and what new tools to use.
For example, clearly Spark has taken a lot of the compute workloads. Gartner’s inquiries about Spark in the same time period have soared to 1120, but over three quarters of them go to analysts outside the data management team. The separation of compute and storage is making its presence felt in who asks, and who answers, the questions that used to be about “Hadoop.” The issues are separate now, and often the teams are too. Compute-oreinted folks are expecting the stores provided to them by their data teams to be accessible with open APIs, and the marketplace offerings at the storage layer will increasingly accommodate those expectations. Another refactoring looms.
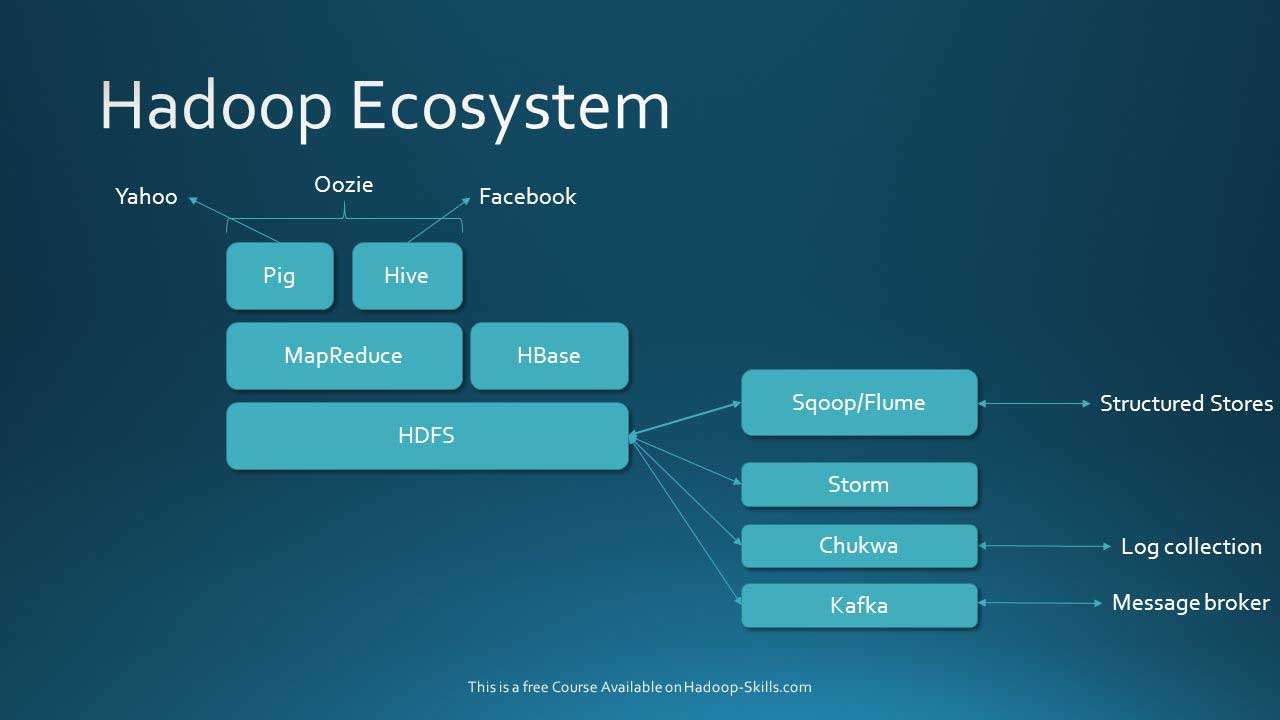
Apache Hadoop is far from dead – it’s still quite active, with the version 3.3 line seeing its first release in July 2020, and several updates have published since in the same stream. It’s still defined on its Apache site by MapReduce, HDFS and YARN, which have continuing value and significant installed bases. But the next steps are in sight. MapReduce is not a preferred tool anymore. HDFS is seeing numerous competitors at the storage layer. YARN is not really found elsewhere, while other open source tools for resource management compete in a dwindling on-premises landscape. It’s not about Hadoop anymore – it’s about what’s next.
Copyright 2022 Trends Edge